Yelp Batch ETL Pipeline — Business Analytics at Scale

A batch ETL pipeline that processes 9.3 GB of Yelp business data to generate analytics and insights about business performance, customer reviews, and popularity trends.
Built with industry-standard tools for big data processing, workflow automation, and data analytics 📊.
🔑 What This Project Does
- Processes large-scale data: Handles 9.3 GB across 5 datasets (150K+ businesses, 7M+ reviews, 2M+ tips)
- 3-layer data pipeline: Raw data → Cleaned data → Business insights (Bronze → Silver → Gold)
- Automated workflows: Scheduled daily/monthly data processing with Apache Airflow
- Business analytics: Calculates popularity scores, rankings, and review metrics for every business
- Production-ready: Fully containerized with Docker, runs on any machine
🏗️ How It Works
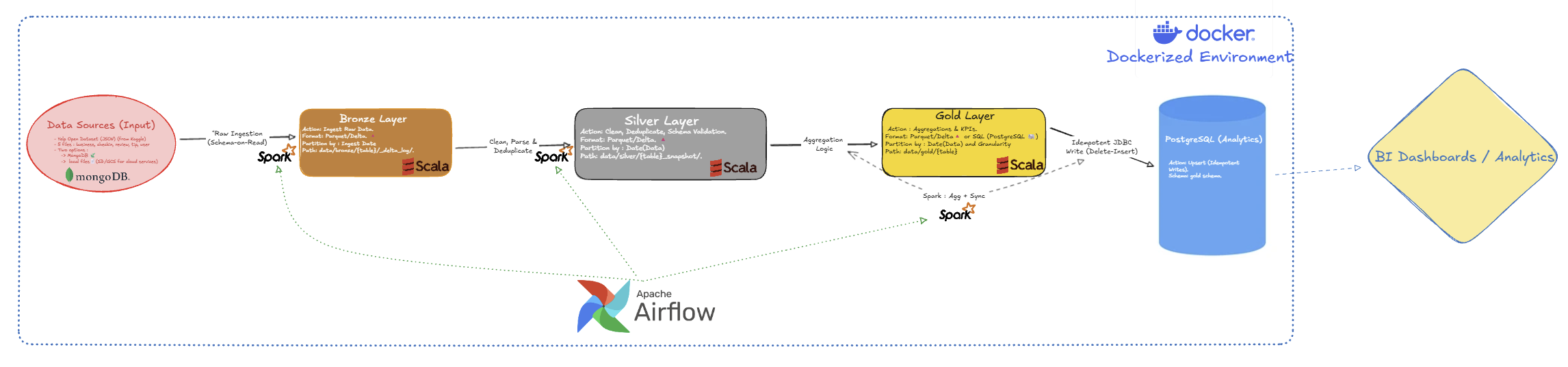
┌─────────────┐ ┌──────────────┐ ┌──────────────┐ ┌─────────────┐
│ Raw Data │────▶│ Bronze │────▶│ Silver │───▶│ Gold │
│ (9.3 GB) │ │ (Raw Storage)│ │ (Cleaned) │ │ (Analytics) │
└─────────────┘ └──────────────┘ └──────────────┘ └─────────────┘
JSON Files Store as-is Remove errors Business KPIs
Standardize data ↓
PostgreSQL Database
What happens at each layer:
- Bronze: Raw data stored without changes (Parquet format)
- Silver: Data cleaned, validated, and organized (Delta Lake format)
- Gold: Final analytics ready for dashboards (PostgreSQL database)
📊 What Each Layer Does
🥉 Bronze Layer — Store Raw Data
Saves all original data exactly as received, no changes. Stores 9.3 GB across 5 files:
- Business data: 150K+ businesses with locations, categories, ratings
- Review data: 7M+ customer reviews with ratings and text
- Tip data: 2M+ short tips from customers
- Check-in data: Visit frequency over time
- User data: Customer profiles and social connections
Storage: Parquet files (columnar format for fast queries)
🥈 Silver Layer — Clean & Organize
Fixes data quality issues and prepares data for analysis:
- Remove duplicate records
- Fix invalid values (e.g., ratings outside 1-5 range)
- Standardize text (uppercase states, trim spaces)
- Organize by date for time-based analysis
Storage: Delta Lake tables (supports updates and versioning)
🥇 Gold Layer — Business Insights
Business Popularity Score Ranks every business by calculating a weighted score from:
- Review ratings (30%)
- Number of reviews (25%)
- Check-in frequency (25%)
- Customer engagement (20%)
Output: Top businesses by city, updated monthly
Review & Tip Metrics Daily and monthly statistics for each business:
- Total reviews, average stars, sentiment trends
- Tips received, compliments earned
- Growth trends over time
Storage: PostgreSQL database (ready for dashboards like Tableau, Power BI)
🛠️ Technology Stack
Data Processing
- Apache Spark 3.5 — Big data processing engine
- Scala 2.12 — Programming language (functional, type-safe)
- SBT — Build and dependency management
Workflow Automation
- Apache Airflow 3.0 — Orchestrates daily/monthly data processing
- Python 3.12 — Airflow DAG definitions
- Docker Compose — Runs all services together
Data Storage
- Parquet — Bronze layer (raw data storage)
- Delta Lake 3.2 — Silver & Gold layers (supports versioning and updates)
- PostgreSQL 13 — Final analytics database
- MongoDB 7 (Optional) — Can load raw data from MongoDB instead of files
Deployment
- Docker — Everything runs in containers (portable, reproducible)
- Typesafe Config — Manages different environments (local/dev/prod)
⚙️ Key Features
🔄 Flexible Processing
- Process a single day, a date range, or specific tables only
- Run manually or schedule with Airflow
- Configurable for different environments (local, dev, production)
🎯 Data Quality
- Validates data quality at every step
- Removes duplicates automatically
- Handles missing or invalid data
- Safe to re-run without corrupting data
📈 Performance
- Processes 9.3 GB of data efficiently using distributed computing
- Stores data in optimized formats for fast queries
- Organizes data by date for time-series analysis
🚀 How to Run
Requirements
- Docker (to run all services)
- 10 GB free disk space
- Download Yelp dataset from Kaggle (9.3 GB)
Quick Start
- Clone the repository
- Download Yelp dataset and place in
data/raw/ - Build the application:
sbt clean assembly - Start services:
docker-compose up -d - Access Airflow UI at
http://localhost:8080 - Configure Spark connection in Airflow
- Trigger the pipeline from the UI
The pipeline runs automatically based on schedule, or you can trigger it manually for specific dates.
📊 Sample Outputs
Business Popularity Rankings
SELECT name, city, state, popularity_score, city_rank
FROM gold.business_popularity
WHERE period_month = '2020-01' AND city = 'Philadelphia'
ORDER BY city_rank
LIMIT 5;
| name | city | state | popularity_score | city_rank |
|---|---|---|---|---|
| Terakawa Ramen | Philadelphia | PA | 0.7212 | 1 |
| Vedge Restaurant | Philadelphia | PA | 0.6954 | 2 |
| Zahav | Philadelphia | PA | 0.6823 | 3 |
Daily Review Metrics
SELECT day, measure, SUM(units) as total
FROM gold.fact_review_tip_metrics_wide
WHERE business_id = 'ABC123' AND granularity = 0
GROUP BY day, measure
ORDER BY day DESC;
🔮 Future Enhancements
- Machine Learning — Sentiment analysis on review text
- Interactive dashboards — Build visualizations with Tableau or Power BI
- Cloud deployment — Deploy on AWS,Azure or GCP for scalability
- Advanced analytics — Predictive models for business trends
📁 Project Structure
yelp-batch-project/
├── src/main/scala/com/yelpbatch/
│ ├── app/ # Entry point (Runner.scala)
│ ├── bronze/ # Raw ingestion layer
│ ├── silver/ # Cleaned transformation layer
│ ├── gold/ # Analytics aggregation layer
│ │ ├── businesspopularity/ # Popularity score computation
│ │ └── factreviewtip/ # Review & tip metrics
│ └── utils/ # Common utilities (IOUtils, DateUtils, etc.)
├── airflow/
│ ├── dags/ # Airflow DAG definitions
│ ├── jars/ # Spark application JAR
│ └── config/ # Airflow configuration
├── sql/ # PostgreSQL schema definitions
├── data/
│ ├── raw/ # Source JSON files (9.3 GB)
│ ├── bronze/ # Raw Parquet files
│ ├── silver/ # Delta Lake tables
│ └── gold/ # Gold Delta tables (pre-PostgreSQL)
├── docker-compose.yaml # Multi-container orchestration
└── build.sbt # Scala build definition
🎓 Skills Demonstrated
✅ Data Engineering — ETL pipeline design, data quality, multi-layer architecture
✅ Big Data Processing — Apache Spark for distributed computing at scale
✅ Programming — Scala (functional programming), Python (automation)
✅ Workflow Orchestration — Apache Airflow for scheduling and monitoring
✅ Databases — PostgreSQL (analytics), Delta Lake (versioning), MongoDB (NoSQL)
✅ DevOps — Docker containerization, multi-service orchestration
✅ Data Modeling — Analytics tables, KPIs, business metrics
📜 License
This project is licensed under the MIT License.
🔗 Links
- GitHub Repository: yelp-batch-pipeline
- Dataset Source: Yelp Open Dataset (Kaggle)
- Documentation: See
/README.mdand/sql/README.md
Built with ❤️ by Aurélien