NBA ML Pipeline — Predict Player Performance

An end-to-end, reproducible machine learning pipeline to forecast NBA player points from historical data.
The project combines data engineering 🏗️, feature engineering 🧩, and ML modeling 🤖, designed for both local experiments 💻 and cloud deployment ☁️.
🔑 Key Highlights
- Data pipeline 🛠️: ingest NBA stats via
nba_api; clean & build per-game player features (rolling means, usage/pace proxies, opponent strength, rest days). - Modeling 📊: baseline regressors → LightGBM; time-aware CV; metrics: MAE, RMSE.
- Inference 🚀: batch predictions for upcoming slates; outputs: local CSV or BigQuery.
- Engineering 🧱: modular repo; env pinning; Docker 🐳; deploy on Cloud Run ☁️; one-command
run_all.sh.
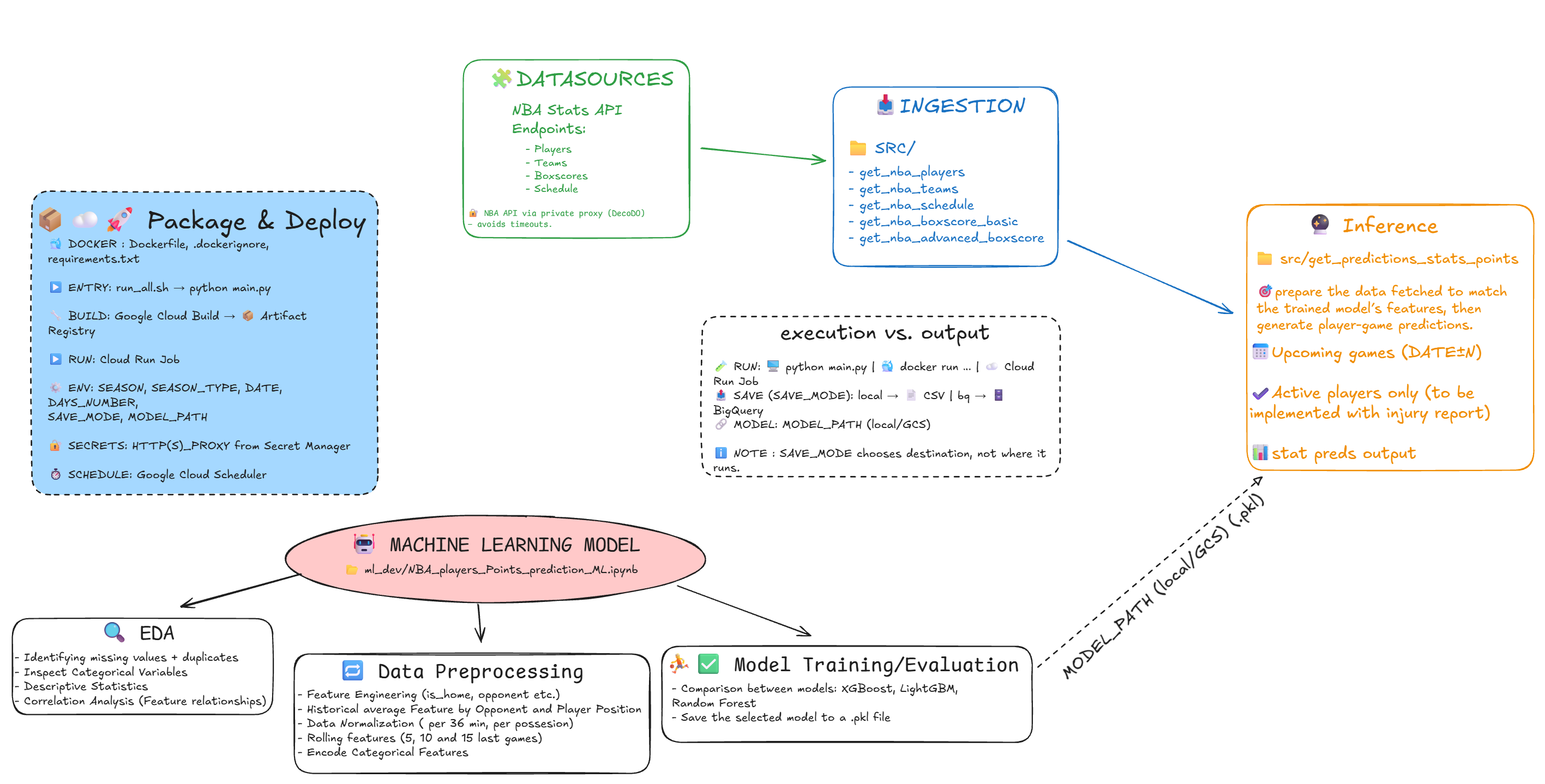
🛠️ Pipeline Architecture
🔮 Next Steps
- Add automatic retraining & evaluation 🔁.
- Extend predictions to assists, rebounds, turnovers 🏆.
- Integrate injury & lineup data 🏥.
- Enhance explainability with SHAP values for feature impact 💡.